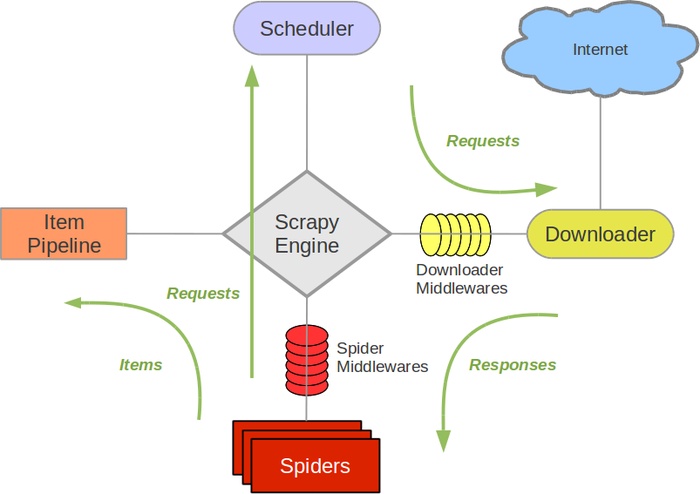
|
|
@@ -1,2 +1,145 @@
|
|
|
## 并发下载
|
|
|
|
|
|
+### 多线程和多进程回顾
|
|
|
+
|
|
|
+
|
|
|
+
|
|
|
+### 实例 - 多线程下载“手机搜狐网”所有页面。
|
|
|
+
|
|
|
+```Python
|
|
|
+
|
|
|
+from enum import Enum, unique
|
|
|
+from queue import Queue
|
|
|
+from random import random
|
|
|
+from threading import Thread, current_thread
|
|
|
+from time import sleep
|
|
|
+from urllib.parse import urlparse
|
|
|
+
|
|
|
+import requests
|
|
|
+from bs4 import BeautifulSoup
|
|
|
+
|
|
|
+
|
|
|
+@unique
|
|
|
+class SpiderStatus(Enum):
|
|
|
+ IDLE = 0
|
|
|
+ WORKING = 1
|
|
|
+
|
|
|
+
|
|
|
+def decode_page(page_bytes, charsets=('utf-8',)):
|
|
|
+ page_html = None
|
|
|
+ for charset in charsets:
|
|
|
+ try:
|
|
|
+ page_html = page_bytes.decode(charset)
|
|
|
+ break
|
|
|
+ except UnicodeDecodeError:
|
|
|
+ pass
|
|
|
+ return page_html
|
|
|
+
|
|
|
+
|
|
|
+class Retry(object):
|
|
|
+
|
|
|
+ def __init__(self, *, retry_times=3,
|
|
|
+ wait_secs=5, errors=(Exception, )):
|
|
|
+ self.retry_times = retry_times
|
|
|
+ self.wait_secs = wait_secs
|
|
|
+ self.errors = errors
|
|
|
+
|
|
|
+ def __call__(self, fn):
|
|
|
+
|
|
|
+ def wrapper(*args, **kwargs):
|
|
|
+ for _ in range(self.retry_times):
|
|
|
+ try:
|
|
|
+ return fn(*args, **kwargs)
|
|
|
+ except self.errors as e:
|
|
|
+ print(e)
|
|
|
+ sleep((random() + 1) * self.wait_secs)
|
|
|
+ return None
|
|
|
+
|
|
|
+ return wrapper
|
|
|
+
|
|
|
+
|
|
|
+class Spider(object):
|
|
|
+
|
|
|
+ def __init__(self):
|
|
|
+ self.status = SpiderStatus.IDLE
|
|
|
+
|
|
|
+ @Retry()
|
|
|
+ def fetch(self, current_url, *, charsets=('utf-8', ),
|
|
|
+ user_agent=None, proxies=None):
|
|
|
+ thread_name = current_thread().name
|
|
|
+ print(f'[{thread_name}]: {current_url}')
|
|
|
+ headers = {'user-agent': user_agent} if user_agent else {}
|
|
|
+ resp = requests.get(current_url,
|
|
|
+ headers=headers, proxies=proxies)
|
|
|
+ return decode_page(resp.content, charsets) \
|
|
|
+ if resp.status_code == 200 else None
|
|
|
+
|
|
|
+ def parse(self, html_page, *, domain='m.sohu.com'):
|
|
|
+ soup = BeautifulSoup(html_page, 'lxml')
|
|
|
+ url_links = []
|
|
|
+ for a_tag in soup.body.select('a[href]'):
|
|
|
+ parser = urlparse(a_tag.attrs['href'])
|
|
|
+ scheme = parser.scheme or 'http'
|
|
|
+ netloc = parser.netloc or domain
|
|
|
+ if scheme != 'javascript' and netloc == domain:
|
|
|
+ path = parser.path
|
|
|
+ query = '?' + parser.query if parser.query else ''
|
|
|
+ full_url = f'{scheme}://{netloc}{path}{query}'
|
|
|
+ if full_url not in visited_urls:
|
|
|
+ url_links.append(full_url)
|
|
|
+ return url_links
|
|
|
+
|
|
|
+ def extract(self, html_page):
|
|
|
+ pass
|
|
|
+
|
|
|
+ def store(self, data_dict):
|
|
|
+ pass
|
|
|
+
|
|
|
+
|
|
|
+class SpiderThread(Thread):
|
|
|
+
|
|
|
+ def __init__(self, name, spider, tasks_queue):
|
|
|
+ super().__init__(name=name, daemon=True)
|
|
|
+ self.spider = spider
|
|
|
+ self.tasks_queue = tasks_queue
|
|
|
+
|
|
|
+ def run(self):
|
|
|
+ while True:
|
|
|
+ current_url = self.tasks_queue.get()
|
|
|
+ visited_urls.add(current_url)
|
|
|
+ self.spider.status = SpiderStatus.WORKING
|
|
|
+ html_page = self.spider.fetch(current_url)
|
|
|
+ if html_page not in [None, '']:
|
|
|
+ url_links = self.spider.parse(html_page)
|
|
|
+ for url_link in url_links:
|
|
|
+ self.tasks_queue.put(url_link)
|
|
|
+ self.spider.status = SpiderStatus.IDLE
|
|
|
+
|
|
|
+
|
|
|
+def is_any_alive(spider_threads):
|
|
|
+ return any([spider_thread.spider.status == SpiderStatus.WORKING
|
|
|
+ for spider_thread in spider_threads])
|
|
|
+
|
|
|
+
|
|
|
+visited_urls = set()
|
|
|
+
|
|
|
+
|
|
|
+def main():
|
|
|
+ task_queue = Queue()
|
|
|
+ task_queue.put('http://m.sohu.com/')
|
|
|
+ spider_threads = [SpiderThread('thread-%d' % i, Spider(), task_queue)
|
|
|
+ for i in range(10)]
|
|
|
+ for spider_thread in spider_threads:
|
|
|
+ spider_thread.start()
|
|
|
+
|
|
|
+ while not task_queue.empty() or is_any_alive(spider_threads):
|
|
|
+ sleep(5)
|
|
|
+
|
|
|
+ print('Over!')
|
|
|
+
|
|
|
+
|
|
|
+if __name__ == '__main__':
|
|
|
+ main()
|
|
|
+
|
|
|
+```
|
|
|
+
|

 jackfrued
jackfrued
{kind=link}